
PCP: Performance Co-Pilot
Performance Co-Pilot (PCP) es un conjunto de herramientas de código abierto diseñado para la monitorización, análisis y visualización del rendimiento de sistemas distribuidos.
Es extremadamente potente porque permite recolectar métricas tanto de hardware como de software en tiempo real y de forma histórica.
Para que veais si es realmente útil y potente, PCP la usan empresas como Netflix, Red Hat, Fujitsu, IBM, HP, así como numerosos bancos, etc.
Veamos el porqué es una herramienta realmente útil y qué la hace tan especial....
¿Cómo funciona?
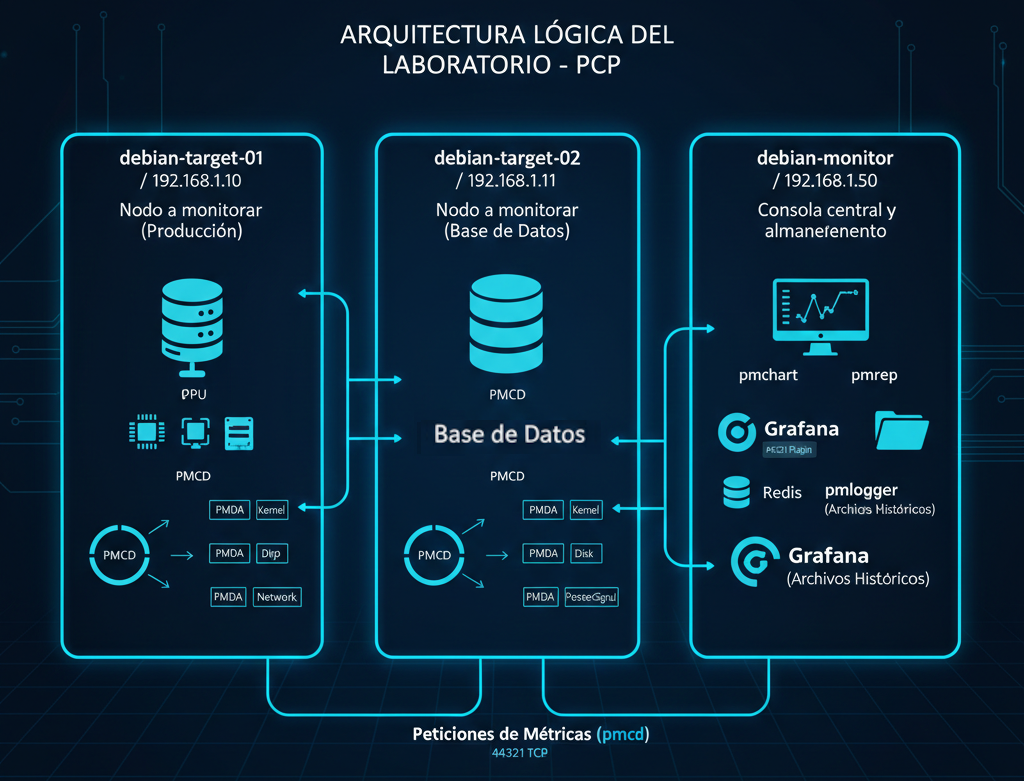
PCP utiliza una arquitectura de tipo agente-recolector que separa la obtención de datos del análisis de los mismos:
- PMDA (Performance Metrics Domain Agents): Son agentes especializados que "viven" en el sistema y extraen datos específicos (del kernel, de bases de datos como PostgreSQL, de la red, etc.).
- PMCD (Performance Metrics Collector Daemon): Es el servicio central que coordina a los agentes y responde a las peticiones de los clientes.
- Clientes de Monitorización: Herramientas que solicitan y muestran los datos, como
pmlogger(para grabar datos) opmchart(para gráficas).
Características Principales
- Bajo impacto (Low Overhead): Está diseñado para ejecutarse en servidores de producción críticos sin consumir recursos significativos.
- Modo Histórico: No solo ves lo que pasa "ahora", PCP puede grabar sesiones para que realices una "autopsia" del rendimiento de un servidor días después de un incidente.
- Extensibilidad: Puedes escribir tus propios agentes (PMDAs) en C, C++, Perl o Python para medir prácticamente cualquier cosa.
- Distribuido: Puedes monitorear múltiples hosts remotos desde una sola consola central.
Soporta también la monitorización de contenedores sin tener que instalar nada dentro de ellos.
Herramientas Comunes del Toolkit
| Herramienta | Función |
|---|---|
pmstat |
Muestra estadísticas generales del sistema (similar a vmstat). |
pminfo |
Enumera todas las métricas disponibles en un sistema. |
pmlogger |
Archiva métricas en el disco para análisis posterior. |
pmrep |
Genera reportes de métricas personalizados en formato texto. |
pcp-htop |
Una versión del conocido htop impulsada por los datos de PCP. |
¿Por qué usarlo en lugar de top o iostat?
Mientras que las herramientas tradicionales son "vistas rápidas" de un momento específico, PCP es una infraestructura completa.
Permite correlacionar, por ejemplo, un pico de latencia en una base de datos con una interrupción específica en la tarjeta de red, todo desde una misma línea de tiempo y con una precisión de milisegundos.
Documentación Oficial
En su web oficial, podeis profundizar sobre la herramientas, instalación y configuraciones avanzadas: https://pcp.io
Incluso existe un repositorio para poder usarlo mediante Ansible: https://github.com/performancecopilot/ansible-pcp
Laboratorio práctico
Para explicar como funciona vamos a plantear un escenario práctico mediante la creación un laboratorio muy sencillo de tipo Arquitectura Distribuida.
En este laboratorio, separaremos los roles para demostrar la capacidad de red de PCP.
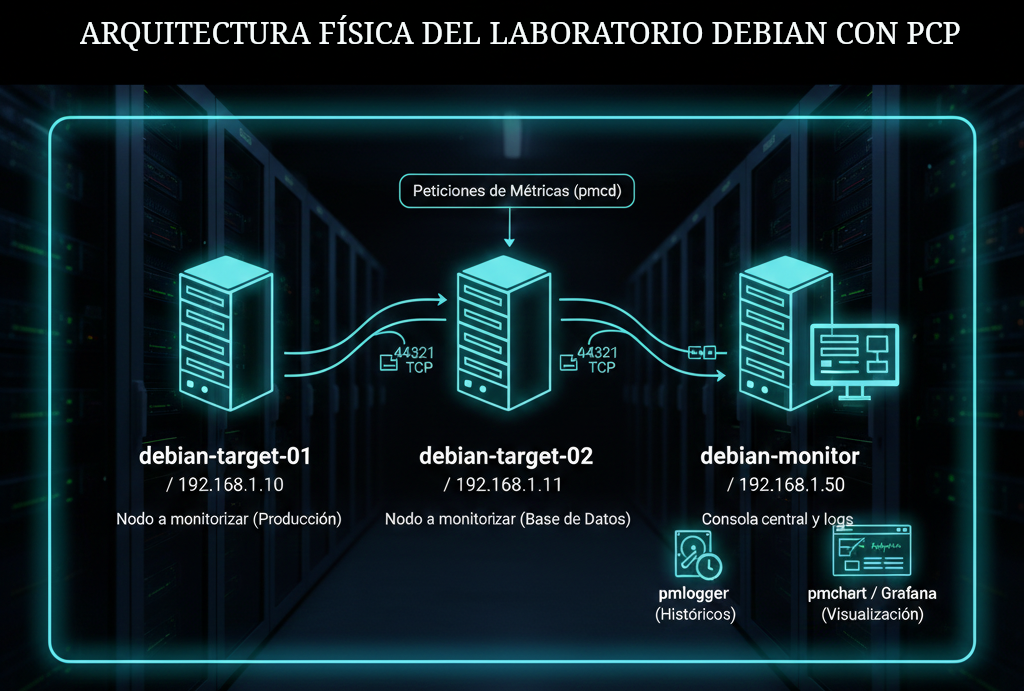
1. Arquitectura Física/Lógica del Laboratorio
Imagina un entorno con tres nodos Debian:
- Nodo A y Nodo B (Destinos): Servidores de aplicaciones que queremos observar.
- Nodo C (Collector/Monitor): La estación de trabajo o servidor central donde visualizamos y almacenamos los datos.
| Host | IP (Ejemplo) | Rol |
|---|---|---|
debian-target-01 |
192.168.1.10 |
Nodo a monitorear (Producción) |
debian-target-02 |
192.168.1.11 |
Nodo a monitorear (Base de Datos) |
debian-monitor |
192.168.1.50 |
Consola central y almacenamiento de logs |
2. Software Necesario
En los Servidores a Monitorizar (Destinos)
Solo necesitamos el "recolector" mínimo y los agentes de métricas.
- Paquete:
pcp - Servicio principal:
pmcd(Performance Metrics Collector Daemon).
En el Servidor que Monitoriza (Collector)
Necesitamos las herramientas de análisis y el demonio de registro.
- Paquetes:
pcp,pcp-gui(para gráficas),pcp-conf. - Servicio principal:
pmlogger(si queremos guardar históricos) y las herramientas cliente (pmchart,pmrep).
3. Configuración para Servidores Monitorizados (Destinos)
El objetivo aquí es permitir que el debian-monitor pueda pedir datos de forma remota.
Métodos de Instalación:
- Instalación Estándard
sudo apt update && sudo apt install pcp
Recomendado si quieres tener control total de que agentes se activan, que puertos se abren y que seguridad se aplica.
- Instalación Automática
sudo apt update && sudo apt install pcp-zeroconf
pcp-zeroconf es un meta-paquete que realiza todo el proceso de forma automatizada, instala pcp, aplica una configuración automática y habilita e inicia el servicio en cada uno de los nodos.
Pasos a realizar tras la instalación
- Habilitar acceso remoto en PMCD:
Por defecto, PCP en Debian suele escuchar solo enlocalhost. Editamos la configuración y verificamos que el puerto 44321 (TCP) esté abierto en el firewall. - Habilitar Agentes (Opcional): Si quieres monitorizar algo específico como por ejemplo PostgreSQL:
cd /var/lib/pcp/pmdas/postgresql
sudo ./Install
- Iniciar Servicio:
sudo systemctl enable --now pmcd
4. Configuración del Servidor que Recolecta y Monitoriza
Aquí es donde ocurre toda la "magia" del análisis.
A. Monitorización en Tiempo Real
Para ver qué pasa en el Nodo A desde el servidor central:
# Ver estadísticas de CPU del nodo remoto cada segundo
pmstat -h 192.168.1.10 -t 1sec
B. Configuración de Grabación Automática (pmlogger)
Para que el monitor guarde los registros históricos de los nodos remotos, editamos el archivo de control de pmlogger:
- Archivo:
/etc/pcp/pmlogger/control - Añadimos una línea para cada nodo:
# Hostname Primary? Socks? LogDir Config
192.168.1.10 n n /var/log/pcp/pmlogger/node01 -c config.default
192.168.1.11 n n /var/log/pcp/pmlogger/node02 -c config.default
C. Visualización Gráfica
Si estás en un entorno gráfico o tu escritorio Linux, lanza pmchart:
pmchart -h 192.168.1.10 -h 192.168.1.11
Esto abrirá una interfaz donde puedes añadir "charts" (gráficas) comparando el rendimiento de ambos servidores en la misma pantalla.
Resumen
- Puerto Clave: 44321 (TCP).
- Concepto clave: El nodo monitorizado es "pasivo" (solo sirve datos), el nodo monitor es "activo" (pide y guarda).
- Ventaja Debian: La instalación es limpia y los servicios de PCP están muy bien integrados en
systemd
Extensibilidad y Analisis Forense con PCP
Veamos dos ejemplos pare ver el potencial de PCP.
Vamos a ver la extensibilidad mediante Python PMDA y la potencia de análisis forense mediante pmlogger de PCP.
1. Creación de una Métrica Personalizada (Python PMDA)
PCP permite crear agentes (PMDAs) de forma sencilla.
Imagina que quieres monitorizar el número de usuarios logueados en una aplicación específica o el estado de un sensor.
Archivo: /var/lib/pcp/pmdas/app_monitor/pmda_app.py
Este script simula una métrica simple que cuenta usuarios activos.
from pcp.pmda import SimplePMDA, pmda_metric
from pcp.pmda import PM_TYPE_U32, PM_INDOM_NULL, PM_SEM_INSTANT
class AppMonitorPMDA(SimplePMDA):
def __init__(self, name):
super(AppMonitorPMDA, self).__init__(name)
# Definimos la métrica: app.users_active
self.add_metric('app.users_active',
pmda_metric(PM_TYPE_U32, PM_INDOM_NULL, PM_SEM_INSTANT, 'count'),
'Usuarios activos en la App')
def fetch_metrics(self):
# Aquí iría la lógica real (ej. query a DB o lectura de logs)
# Para el laboratorio, devolvemos un valor estático o aleatorio
return {'app.users_active': 42}
if __name__ == '__main__':
AppMonitorPMDA('app_monitor').run()
Instalación en el Destino:
- Copia el script al directorio indicado.
- Ejecuta el script de instalación que PCP proporciona para Python PMDAs (normalmente
Install). - Desde el Servidor Monitor, ya puedes consultar los datos tras el "Install" en el nodo:
pminfo -f app.users_active -h 192.168.1.10
2. Caso de Uso: Detección de Tráfico Inusual
Para detectar anomalías como picos de I/O o tráfico de red fuera de horas, usaremos pmrep (reportes) y pmlogger (archivos históricos).
Escenario A: Tráfico de Red fuera de Horario (Análisis de Archivos)
Si tienes configurado el pmlogger en el servidor monitor, puedes analizar lo que pasó anoche a las 3:00 AM:
# Analizar el archivo de log de anoche filtrando por interfaces de red
# -a: ruta al archivo de log
# -S/ -T: ventana de tiempo sospechosa
pmrep -a /var/log/pcp/pmlogger/node01/20260301.0 -S "02:00" -T "04:00" network.interface.out.bytes
Escenario B: Alerta de Picos Excesivos de I/O (Tiempo Real)
Puedes usar pmie (Performance Metrics Inference Engine) para ejecutar una acción si se supera un umbral de trafico de entrada y salida (exfiltración de datos).
Archivo de reglas (io_alerts.conf):
/* Si el tiempo de lectura de disco es > 500ms por 3 muestras consecutivas */
disk.dev.read_rawactive > 500ms
-> shell "echo 'ALERTA: I/O Excesivo en ' + $host | mail -s 'PCP Alert' admin@empresa.com";
Ejecución:
pmie -t 5sec io_alerts.conf
PDMA Disponibles
Los PDMAs son componentes que actuan como puente entre el sistema o un aplicación y el demonio recolector pmcd su funcion es simplemente recoger datos crudos de una fuente y traducirlos al formato que entiente PCP.
Existen PDMAs ya creados especializados en la parte del Kernel, Disco, Redes, Bases de datos, Servidores Web, Gestores de colas, Servidores de ficheros, Recursos compartidos, etc...
PMDAs del Sistema Operativo (Infraestructura Base)
Estos agentes están casi siempre activos o disponibles de inmediato.
| Agente | Nombre del Dominio | Descripción |
kernel | kernel | La fuente principal: CPU, Memoria, Carga del sistema, Entradas/Salidas. |
linux | linux | Métricas específicas de Linux: cgroups, /proc filesystem, interrupciones. |
proc | proc | Estadísticas detalladas de procesos individuales (memoria, CPU por PID). |
kvm | kvm | Rendimiento de máquinas virtuales sobre Kernel-based Virtual Machine. |
PMDAs de Almacenamiento (Discos y Ficheros)
| Agente | Descripción |
disk | Estadísticas de I/O de discos físicos y particiones (latencia, throughput). |
xfs | Métricas internas del sistema de archivos XFS. |
jfs | Métricas del sistema de archivos JFS. |
nfsclient | Rendimiento del cliente NFS (montajes remotos). |
nfsserver | Rendimiento del servidor NFS (carga en el servidor de ficheros). |
trace | Agente de traza de Linux para I/O de bajo nivel. |
PMDAs de Redes y Protocolos
| Agente | Descripción |
network | Estadísticas de interfaces de red: paquetes, bytes, errores, colisiones. |
snmp | CRÍTICO: Permite a PCP actuar como cliente SNMP para obtener métricas de switches, routers, impresoras y servidores físicos. |
infiniband | Rendimiento de redes de altísima velocidad (InfiniBand). |
bonding | Monitorización de interfaces de red agrupadas (bonded interfaces). |
PMDAs de Bases de Datos
| Agente | Descripción |
postgresql | Conexiones activas, transacciones por segundo, tiempos de bloqueo, hit ratio de caché. |
mysql | Métricas de servidor MySQL/MariaDB: queries, hilos, memoria. |
redis | ESENCIAL PARA GRAFANA: Métricas internas de Redis, uso de memoria, claves, comandos. |
oracle | Conexiones a bases de datos Oracle. |
PMDAs de Servidores Web y Aplicaciones
| Agente | Descripción |
apache | Peticiones por segundo, conexiones activas, uso de hilos. |
nginx | Estado de conexiones de Nginx. |
statsd | Permite a las aplicaciones enviar métricas personalizadas a PCP usando el protocolo StatsD. |
prometheus | Permite a PCP consultar endpoints en formato Prometheus (scraping). |
PMDAs de Mensajería y Colas
| Agente | Descripción |
rabbitmq | Estado de colas, mensajes en cola, consumidores, memoria de RabbitMQ. |
jmx | JAVA MANAGEMENT EXTENSIONS: Permite monitorizar cualquier aplicación Java (Tomcat, JBoss, Cassandra) que exponga JMX. |
PDMAs en tu Servidor y qué hace
Para saber los PDMAs que tienes en tu servidor Debian, tan solo tienes que ejecutar el siguiente comando:
ls /var/lib/pcp/pmdasPara consultar la lista de métricas que un agente en uno de los nodos está enviando en ese mismo momento, simplemente ejecuta: pminfo -d [nombre_agente]
# Ejemplo para postgresql
pminfo -d postgresql
Resumen (Puntos clave para uso como herramienta forense)
- Visibilidad Total: Con
pmrepy los filtros de tiempo (-S,-T), puedes ver que PCP funciona como una "caja negra" de un avión para servidores. - Correlación: Se puede mostrar cómo un pico de
network.interface.in.bytescoincide exactamente con un aumento dedisk.dev.write(indicando quizás una subida/descarga masiva de archivos no autorizada). - Simplicidad: El PMDA en Python demuestra que cualquier métrica de negocio puede convertirse en una métrica de sistema en minutos.
Configuración de las Vistas
Veamos ahora como configurar un gráfico visual.
pmchart es una herramienta extremadamente flexible que permite arrastrar y soltar métricas, pero para un laboratorio profesional lo mejor es usar un archivo de vista (.view).
Configuración de la Vista en pmchart
En lugar de buscar métricas manualmente, crearemos un archivo de configuración llamado laboratorio_red_io.view.
Este archivo define qué métricas queremos ver de forma simultánea para correlacionar datos.
Archivo: laboratorio_red_io.view
#pcpview v2.0
# Gráfico de Red vs I/O de Disco
chart title "Tráfico de Red (Salida)"
plot host * metric network.interface.out.bytes [eth0]
chart title "Escritura en Disco"
plot host * metric disk.dev.write [sda]
chart title "Carga del Sistema"
plot host * metric kernel.all.load [1 minute]
Visualización gráfica
Ejecución para Visualización
Desde el Servidor Monitor (el equipo que tiene entorno gráfico), ejecutamos el comando apuntando a nuestros servidores Debian del laboratorio:
# Visualización en tiempo real de dos servidores a la vez
pmchart -h 192.168.1.10 -h 192.168.1.11 -c laboratorio_red_io.view
Si lo que queremos es analizar el tráfico inusual que ocurrió en el pasado (usaremos los logs de pmlogger que mencionamos antes):
# Visualización en modo "Play/Rebobinado" de un archivo de log
pmchart -a /var/log/pcp/pmlogger/node01/20260301.0 -c laboratorio_red_io.view
Interpretación de lo que se visualizamos
En la pantalla de pmchart veremos tres filas de gráficos.
Aquí podemos ver y correlacionar el "tráfico inusual":
- Sincronización de Tiempo: Explica que el eje X es idéntico para todos los gráficos. Si hay un pico de red a las 03:15 AM y un pico de escritura en disco al mismo segundo, es una prueba técnica de que el tráfico de red se está guardando localmente.
- Modo de Reproducción (VCR Mode): Muestra los controles en la parte inferior de
pmchart. Puedes darle a "Play" a una velocidad de 10x para ver cómo evolucionó el sistema durante toda la noche en pocos segundos. - Comparación Multihost: Al usar
-hcon varias IPs, las líneas de diferentes servidores aparecerán con colores distintos en el mismo gráfico. Esto permite ver si el tráfico inusual afectó a un solo nodo o a todo el clúster (ataque DDoS o backup mal configurado).
Truco adicional: Exportar a Imagen para Informes
Si necesitamos disponer de una captura gráfica como prueba para un informe forense (post-mortem):
# Generar un pantallazo (PNG) de la situación actual sin abrir la interfaz
pmchart -h 192.168.1.10 -c laboratorio_red_io.view -v pcp_report.png
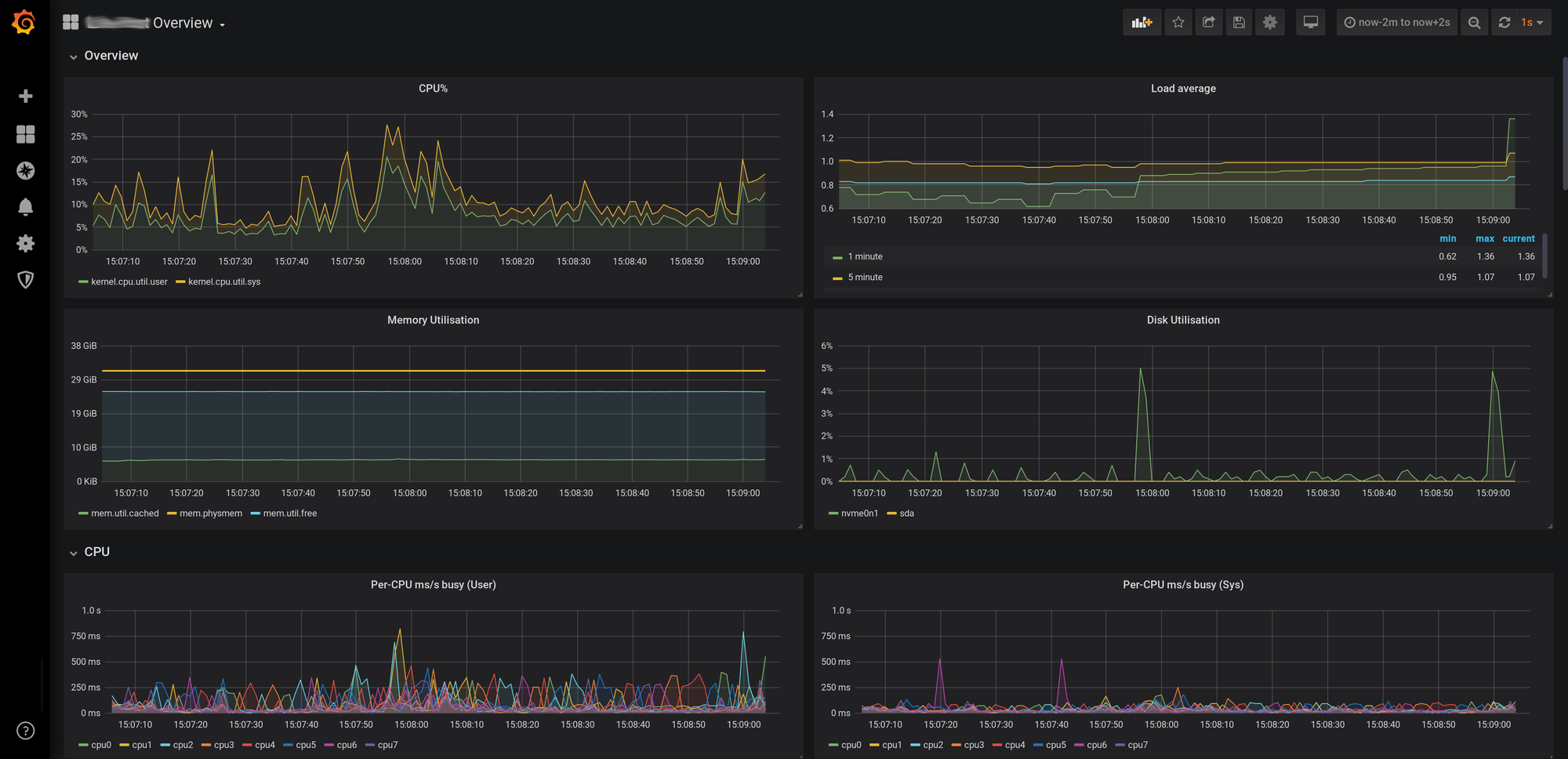
Observabilidad moderna (PCP y Grafana)
Modernicemos todo lo que nos proporciona PCP como herramienta de *analisis forense rápido" usando Grafana que es el estandar para los cuadros de mando (dashboards).
1. Arquitectura de Integración: PCP + Redis + Grafana
Para que Grafana pueda leer datos de PCP de forma eficiente (especialmente datos históricos y de múltiples hosts), necesitamos un componente intermedio llamado pmproxy y una base de datos Redis que actúe como caché de todas las series temporales.
Componentes en el Servidor Monitor (Debian):
pmproxy: El servicio que expone las métricas de PCP vía HTTP/JSON.redis-server: Almacena las métricas para que las consultas de Grafana sean instantáneas.grafana-server: El motor de visualización.grafana-pcp: El plugin oficial que conecta ambos mundos.
2. Instalación en el Servidor Monitor (Debian)
Ejecuta estos pasos en tu nodo central del laboratorio:
# 1. Instalar PCP con soporte para PCP-Redis
sudo apt install pcp pcp-conf libpcp-pmda3-dev redis-server
# 2. Instalar Grafana (Repositorio oficial)
sudo apt install -y apt-transport-https software-properties-common wget
wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee /etc/apt/sources.list.d/grafana.list
sudo apt update && sudo apt install grafana
# 3. Instalar el Plugin de PCP para Grafana
sudo grafana-cli plugins install performancecopilot-pcp-app
# 4. Reiniciar y habilitar servicios
sudo systemctl enable --now pmproxy redis-server grafana-server
3. Configuración del Origen de Datos (Data Source)
- Accede a Grafana:
http://192.168.1.50:3000(Usuario/Clave:admin/admin). - Ve a Plugins > Performance Co-Pilot y haz clic en Enable.
- Añade un nuevo Data Source de tipo PCP Redis.
- URL:
http://localhost:44322(Puerto por defecto depmproxy).
¡Listo! Ya podemos importar los dashboards que vienen por defecto (como "PCP Host Overview").
4. Ejemplo: Panel de "Tráfico Inusual" en Grafana
Ahora ya podemos crear el panel que combine red e I/O con alertas visuales:
- Query (PCP Redis):
network.interface.out.bytes - Visualización: "Time series".
- Umbrales (Thresholds): Configuramos para que la gráfica cambie a Rojo si el tráfico supera los 100 Mbps.
5. Ventajas de usar Grafana y PCP
| Característica | pmchart (Legacy) |
Grafana + PCP (Moderno) |
|---|---|---|
| Interfaz | Aplicación gráfica (Local) | Web (Accesible desde cualquier sitio) |
| Persistencia | Basada en archivos .view |
Dashboards dinámicos en base de datos |
| Alertas | Vía pmie (Consola/Email) |
Visuales, Slack, Discord, PagerDuty |
| Escalabilidad | Un host a la vez (principalmente) | Cientos de hosts centralizados en Redis |
PCP es una vieja herramienta que compite con soluciones de Pago
PCP es quizás una herramienta vieja de Unix pero sólo si la usas solo en modo Legacy.
Si la integras con Redis y Grafana, se convierte en una plataforma de telemetría de última generación.
Si gestionas y configuras PCP, dispones de una herramienta capaz de competir con soluciones de pago como Datadog o New Relic, pero manteniendo todos los datos bajo tu control en tus servidores Debian.
Problemas y Dudas que resuelve PCP
Para finalizar, no hablemos solo de métricas, hablemos de cómo PCP ahorra tiempo, estrés y dinero.
PCP soluciona los problemas reales del día a día de un administrador de sistemas, es lo que se denominan "Puntos de Dolor".
Ejemplos de "Puntos de Dolor":
1. "El servidor va lento, pero no sé por qué" (Visibilidad Total)
- Dolor: Usar
topohtopsolo te muestra el ahora. Si el pico de carga pasó hace 5 minutos, ya no sabes qué proceso lo causó. - Solución PCP: Con
pmloggery la capacidad de reproducir logs, puedes retroceder en el tiempo y ver qué proceso específico (pid) estaba consumiendo CPU o I/O a las 03:00 AM.
2. "La culpa es de la Red... ¿o del Disco?" (Correlación de Métricas)
- Dolor: Tienes herramientas separadas. Una para red (
netstat), otra para disco (iostat), otra para aplicaciones. Correlacionarlas manualmente es un infierno. - Solución PCP: Unifica todo. Puedes tener en un mismo gráfico de Grafana o
pmchartlas métricas de red, disco, CPU y las métricas personalizadas de tu aplicación (app.users_active). Si la red sube y el disco sube a la vez, tienes la causa raíz inmediatamente.
3. "No tengo presupuesto para licencias de APM" (Código Abierto y Bajo Coste)
- Dolor: Soluciones comerciales (Datadog, New Relic) son costosas y cobran por volumen de datos.
- Solución PCP: Es 100% Open Source. Puedes escalar el monitoreo a cientos de servidores Debian sin aumentar los costes de licencias.
4. "Mis servidores de producción no pueden ralentizarse por monitorearlos" (Bajo Impacto)
- Dolor: Algunos agentes de monitoreo consumen tanto recurso como la propia aplicación, afectando al rendimiento.
- Solución PCP: Diseñado con el principio de "bajo impacto" (Low Overhead). Los agentes (
pmda) están escritos en C o Python eficiente, asegurando que el monitoreo no sea el causante del problema.
"Performance Co-Pilot es la diferencia entre adivinar por qué se cayó un servidor y saber exactamente qué pasó."
Análisis de los datos desde el PC del SysAdmin
Una de las grandes ventajas de PCP es su arquitectura cliente-servidor.
No necesitas entrar por SSH a los servidores para ver las gráficas, puedes instalar herramientas gráficas ligeras en tu portátil con Linux y conectarlas remotamente a los servidores de producción.
Herramienta Gráfica Recomendada: pmchart
pmchart es la herramienta nativa de PCP basada en Qt.
Es rápida, eficiente y perfecta para lo que usarla directamente como una aplicación de escritorio desde el PC de un SysAdmin.
1. Instalación en tu portátil (Debian)
Simplemente instala el paquete de herramientas gráficas:
sudo apt update
sudo apt -y install pcp-gui
2. ¿Cómo revisar las gráficas remotamente?
Una vez instalado, puedes abrir pmchart y decirle a qué servidor conectarse en tiempo real.
# Conectarse al servidor de aplicaciones
pmchart -h 192.168.1.10
Puntos claves para tu portátil
- Tiempo Real vs Histórico:
- Para tiempo real, usas
-hy la IP del servidor objetivo. - Si copias los archivos de registro (
/var/log/pcp/pmlogger/...) de tu servidor central a tu portátil, puedes usarpmchart -a /ruta/al/archivo_logpara analizar el pasado sin necesidad de estar conectado.
- Rendimiento en el portátil:
pmchartes muy ligero, apenas consumirá recursos de tu máquina local. - Configuración de vistas: Puedes crear tus propias vistas con las métricas que más te interesen (CPU, Red, I/O) y guardarlas para consultarlas rápido.
Resumen del Laboratorio
- Destinos: Instalar
pcp. - Centralizador: Instalar
pcp+pmproxy+redis(para Grafana Web). - Tu Portátil: Instalar
pcp-gui(parapmchartrápido).
EXTRA: Herramienta pcp-testsuite
pcp-testsuite es una grupo de aplicaciones que incluye herramientas como pcp-test, es el componente fundamental para asegurar la calidad de la implementación de PCP.
¿Qué es pcp-testsuite?
Es un conjunto de herramientas y scripts diseñado específicamente para validar, probar y hacer benchmarking de los componentes de Performance Co-Pilot (PCP).
- No es para monitorizar producción, sino para probar el propio sistema de monitorización.
- Se utiliza principalmente por los desarrolladores que crean nuevos agentes (PMDAs) o por administradores de sistemas que quieren asegurar que PCP está recolectando datos correctamente antes de confiar en él para alertas críticas.
¿Para qué sirve?
Sirve para garantizar la integridad de los datos y el correcto funcionamiento del software PCP.
1. Validación de Agentes Personalizados (PMDAs)
Con el PMDA en Python que creamos antes (app.users_active), pcp-testsuite sirve para verificar que:
- El agente responde correctamente a las peticiones (
pmcd). - Los datos tienen el tipo correcto (entero, flotante, contador).
- No hay fugas de memoria en el agente.
2. Pruebas de Carga y Rendimiento
Permite simular peticiones masivas al demonio pmcd para verificar si el agente personalizado causa cuellos de botella o si pmcd sigue respondiendo bajo estrés.
3. Verificación de logs (pmlogger)
Sirve para comprobar que los archivos de registro (PCP Archives) no están corruptos y que las métricas grabadas coinciden con las reales.
Ejemplo de uso en el Laboratorio
Si estamos desarrollando un PMDA personalizado, usariamos testsuite de la siguiente forma:
- Ejecutar pruebas unitarias del agente:
# Ejecutar pruebas básicas sobre un PMDA específico
/usr/share/pcp/testsuite/bin/pcp-test -pmda app_monitor
- Validar la instalación de PCP:
# Ejecutar un set de pruebas de diagnóstico sobre la instalación actual
pcp-test-suite
Resumen de pcp-testsuite
"Mientras PCP monitoriza el servidor, pcp-testsuite monitoriza que PCP esté realizando bien su trabajo."Esto es esencial para entornos corporativos y de producción, donde la veracidad del dato es crítica para tomar decisiones basadas en esas métricas.


