LLaMA v2 - Tu propio ChatGPT
¿Puedo tener mi propio ChatGPT?
Gracias al movimiento OpenSource, se democratiza todo.
Se han abierto al público en general las denominadas Open-IA para que cualquiera las pueda usar, entrenar, mejorar y por supuesto compartir de nuevo.
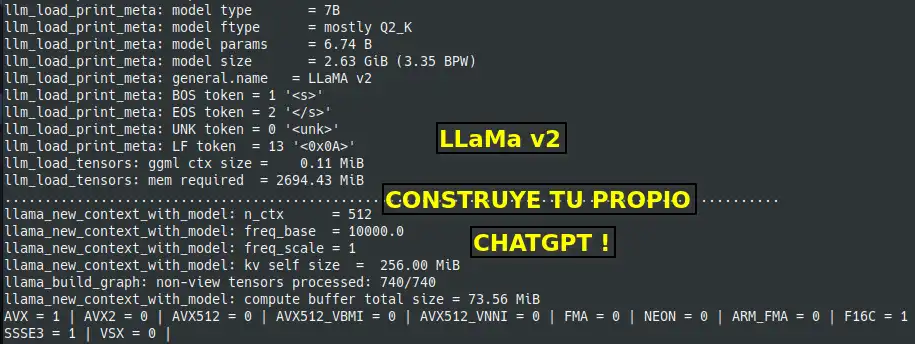
En mi caso estoy usando un contenedor Docker y un modelo 7B de LLaMa v2, para disponer de mi propio ChatGPT al que he llamado SCL-GPT.
GPU en el procesamiento de la IA's
Como seguramente has leido el procesamiento de las IAs se realiza mediante el uso de Hardware especializado, costosas GPU's y gran consumos de energía eléctrica.
Sin embargo existen modelos de IAs que están preparadas para poder usarse mediante el uso de la CPU del equipo si no contamos con una GPU especializada para ello.
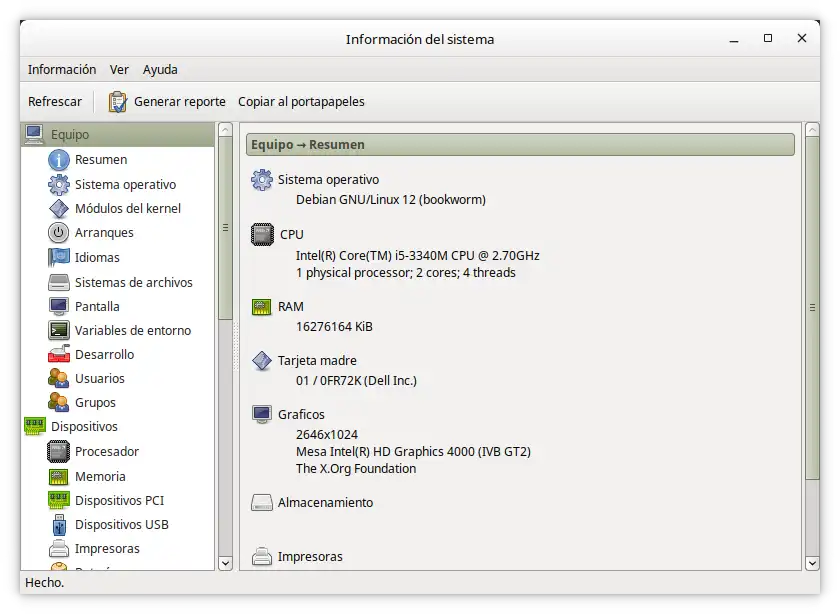
En mi caso, para realizar todas las pruebas y funcionamiento, estoy utilizando mi propio portatil que es un i5 a 2.70GHz y 16 Gb de RAM, con sistema operativo Debian 12.
Como montarte tu propio ChatGPT
No esperes nada "avanzado", no voy a hablar sobre como entrenar un nuevo modelo, simplemente espero que este artículo sea un primer acercamiento al mundo de las IA's , que veas que incluso te puedes descargar y usar una propia sin tener que pagar por el uso de la misma para entretenerte con ella.
Además el uso de contenedores te evita el tener que descargar y configurar en tu propio equipo la enorme cantidad de modulos de python necesarios.
Vamos paso a paso:
- Tener instalado docker en tu equipo.
Puedes leer el artículo sobre como instalarlo en:

2. Crearte una cuenta en Hugging Face para descargar los "modelos" de IA

3. Descargar el modelo de IA "LLaMa v2 7B formato GGUF"

Busca en Huggin Face y descarga el modelo, el fichero a descargar tiene de nombre: llama-2-7b-chat.Q2_K.gguf
4. Crear nuestro Dockerfile para crear la Imagen que iniciará la IA.
En el mismo directorio en el que descargaste el modelo de la IA, crea un fichero de nombre Dockerfile (respeta las mayúsculas y minúsculas).
Editalo y pega el siguiente contenido:
# Usaremos una imagen oficial de Python como base
FROM python
# Fijamos el directorio de trabajo del contenedor
WORKDIR /app
# Copiamos dentro el script que hace que funcione como servidor
COPY ./llama_cpu_server.py /app/llama_cpu_server.py
# Instalamos cualquier paquete necesario especificado en requirements.txt
RUN pip install llama-cpp-python
RUN pip install Flask
# Exponemos el puerto 5000 para conectarnos al contenedor
EXPOSE 5000
# Ejecutamos el servidor python cuando se inicie el contenedor
CMD ["python", "llama_cpu_server.py"]
Si lo prefieres lo puedes descargar:
5. Creamos en la misma ruta el fichero 'llama_cpu_server.py', deberá tener el siguiente código:
from flask import Flask, request, jsonify
from llama_cpp import Llama
# Create a Flask object
app = Flask("Llama server")
model = None
@app.route('/llama', methods=['POST'])
def generate_response():
global model
try:
data = request.get_json()
# Check if the required fields are present in the JSON data
if 'system_message' in data and 'user_message' in data and 'max_tokens' in data:
system_message = data['system_message']
user_message = data['user_message']
max_tokens = int(data['max_tokens'])
# Prompt creation
prompt = f"""<s>[INST] <<SYS>>
{system_message}
<</SYS>>
{user_message} [/INST]"""
# Create the model if it was not previously created
if model is None:
model_path = "./llama-2-7b-chat.Q2_K.gguf"
model = Llama(model_path=model_path)
# Run the model
output = model(prompt, max_tokens=max_tokens, echo=True)
return jsonify(output)
else:
return jsonify({"error": "Missing required parameters"}), 400
except Exception as e:
return jsonify({"Error": str(e)}), 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=True)Si lo prefieres lo puedes descargar:
6. Ahora debemos de crear la imagen 'llama2', para ello escribe en la terminal:
docker build -t llama2 .
7. Iniciar IA. Preguntar a la IA. Detener la IA.
Para evitar que tengas que iniciar a mano el contenedor, realizar las conexiones y/o peticiones a la API de la IA de Llama 2, extraer el contenido del JSON devuelto y por ultimo detener el contenedor, hoy tienes un 3x1. Con un único fichero bash, puedes empezar a usar la IA en modo local, con lo que además de evitar un pago, tendrás total privacidad en su uso...
Crea un fichero en el mismo directorio en el que descargaste el modelo GGUF, y ponle como nombre 'ia.sh', editalo y pega el siguiente contenido en él:
#!/bin/bash
# Establecer VALORES API de ChatGPT Local
SCLGPT_URL="http://127.0.0.1:5000/llama"
MAX_TOKENS=100
SALUDO_IA="Eres un asistente genial" #You are a helpful assistant
if [ "$1" == "" ] ; then
MAX_TOKENS=100
else
if [ $1 -gt 100 ] ; then
MAX_TOKENS=$1
else
MAX_TOKENS=100
fi
fi
# Funciones docker IA
function StarIA() {
echo "Iniciando IA ..."
StopIA
docker run -d --name sclgpt -ti -p 5000:5000 -v $(pwd)/llama-2-7b-chat.Q2_K.gguf:/app/llama-2-7b-chat.Q2_K.gguf llama2
}
function StopIA() {
docker stop sclgpt 2>/dev/null
docker rm sclgpt 2>/dev/null
}
function TimeIA() {
echo -e "\nProcesado en: $(docker logs sclgpt |grep 'total time'|tail -1|awk '{print $5" milisegundos"}')"
}
# ----- Main / Principal ---------------------------
StarIA
clear
echo
echo "----------------------------------------"
echo " Conversar con SoloConLinux-GPT [SCL-GPT]"
echo "----------------------------------------"
echo
# Bucle principal del programa
while true; do
# Solicitar una pregunta al usuario
echo -n "[$USER] escribe tu pregunta (o 'salir'): "
read SCL_PREGUNTA
# Si escribe "salir", salimos del programa
if [ "$SCL_PREGUNTA" == "salir" ]; then
break
fi
# Utiliza la herramienta "curl" en modo silencioso para enviar la pregunta al API de ChatGPT y obtener la respuesta del chatbot
echo -e "\n ... SCL-GPT pensando ...\n"
# Extrae la respuesta del chatbot de la respuesta JSON de la API
# Muestra la respuesta del chatbot en la consola
echo -e "[SCL-GPT]:\n$(curl -s $SCLGPT_URL -H "Content-Type: application/json" -d "{\"system_message\": \"$SALUDO_IA\", \"user_message\": \"$SCL_PREGUNTA\", \"max_tokens\": $MAX_TOKENS}" | grep '"text"' | sed 's/`//g' | awk -F 'SYS>>' '{print $3}' | awk -F 'INST]' '{print $2}')"
TimeIA
echo -e "\n----------------------------------------------------------------------------------"
done
StopIA
Si lo prefieres lo puedes descargar:
Para poder usar el script debes de darles permisos de ejecución, para ello desde la terminal ejecuta:
chmod +x ia.sh
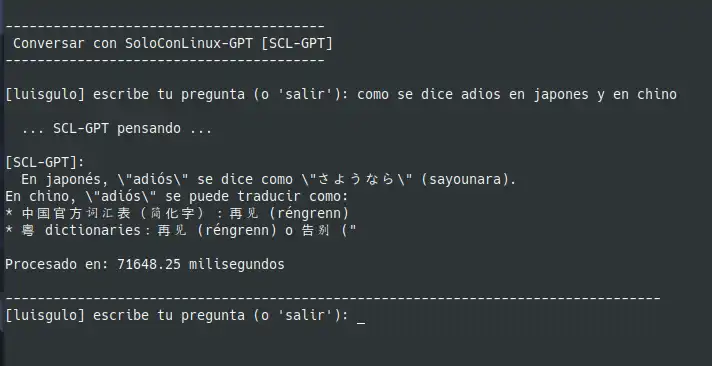
Usando la IA
Si has realizado todos los pasos anteriores sin saltarte nada y teniendo todos los ficheros necesarios (.gguf) en el mismo directorio, ya puedes iniciar tu IA y comenzar a preguntarla.
Por defecto se le pregunta a la IA con un valor de 100 tokens, si ves que las respuestas son "cortas", puedes aumentar el valor de número de tokens a usar. Simplemente pasa el numero deseado de tokens como parámetro a la hora de ejecutar el script.
Nota: A mayor número de tokens indicados mejor respuesto pero mayor consumo de CPU (y lentitud) a la hora de responder.
Para usarla, escribe en la terminal:
# Usar la IA
./ia.sh
# Usar la IA con 250 tokens
./ia.sh 250
Diviertete preguntando a la IA lo que quieras, en cuanto quieras finalizar tus consultas, simplemente escribe salir.
Uso de otros Modelos de IA
Si te descargas otro modelo diferente, y quieres usarlo, deberás ajustar el nombre del fichero descargado en los siguientes ficheros:
-
llama-cpu_server.py En la línea:
model_path = "./llama-2-7b-chat.Q2_K.gguf" -
ia.sh En la línea:
docker run -d --name sclgpt -ti -p 5000:5000 -v $(pwd)/llama-2-7b-chat.Q2_K.gguf:/app/llama-2-7b-chat.Q2_K.gguf llama2
Nota: El formato INT4 nativo de BigDL-LLM actualmente admite la familia de modelos LLaMA (como Vicuna, Guanaco, Koala, Baize, WizardLM, etc.), LLaMA 2 (como Llama-2-7B-chat, Llama-2-13B-chat ), GPT-NeoX (como RedPajama), BLOOM (como Phoenix) y StarCoder.