Audapolis. Análisis de la aplicación para extraer Texto de Audio/Vídeo
¿Cómo funciona Audapolis?
Audapolis es una aplicación Cliente-Servidor, en la que la parte gráfica de la aplicación está desarrollada en Electron.
La parte del servidor, que se ejecuta en local en tu equipo, está desarrollada en Python.
El código de la aplicación está en Github y la puedes ver en el siguiente enlace:
 bugbakery
bugbakeryAl iniciar la aplicación, se detecta si es necesario descargar un "modelo de traducción" para el idioma deseado.
Dependiendo del modelo, puedes tener más de una opción, las hay que ocupan apenas 39 Mb hasta las que ocupan más de 1.5 Gb.
Este modelo, es el que usará el servidor local para realizar el proceso de interpretación del audio del fichero y transcribir el texto correspondiente.
A mayor tamaño del modelo, mejora la traducción, pero el consumo de recursos de tu equipo se dispará hasta el punto que puedas pensar que se ha "colgado".
Otra punto importante que tienes que tener en cuenta, es que mientras dura el proceso de reconocimiento del audio, tu dispositivo de audio va a quedar desactivado (capturado por la aplicación audapolis).
Instalación de Audapolis
La versión disponible actualmente es la v0.3.0 y puedes descargarlo tanto en version AppImage como en versión de paquete Debian:
bugbakeryDetección de voces en Audapolis
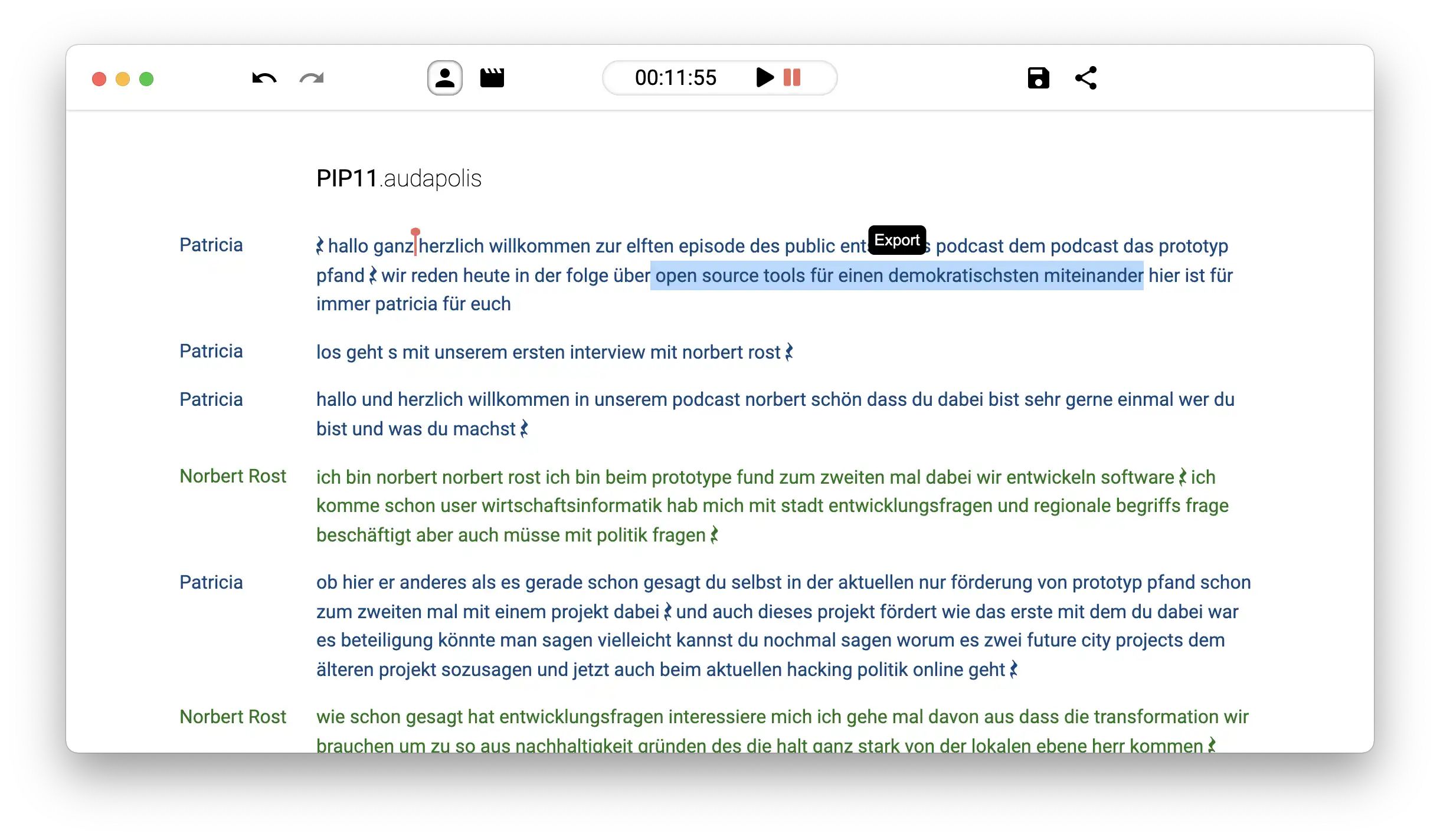
Cuando indiques el audio o vídeo del que deseas extraer el texto, debes indicar si intervienen una o varias personas en el mismo.
Puedes indicar desde 1 a 4 personas, en la detección de voces, para extraer el texto, la aplicación se encargará de reconocer la tonalidad de cada uno de los que intervienen y separar el texto de cada una de ellas:
Ventajas e Inconvenientes
Ventaja 1: La aplicación reconoce bastante bien el audio hablado en español aunque falla en algunas palabras particulares, pero nada que no se pueda ignorar y corregir y editar en el texto a posteriori.
Ventaja 2: El reconocimiento del audio se realiza en local, no hay datos que puedan filtrarse al exterior en el proceso de extracción del texto.
Inconveniente: Tiene un consumo excesivo de recursos en el proceso de detección del audio y extracción a texto.