
Acelerando Procesos rsync
¿Qué es rsync?
Lo primero de todo es explicar que es rsyncpara el que no lo conozca.
rsync es una aplicación libre para sistemas de tipo Linux/Unix y Microsoft Windows que ofrece transmisión eficiente de datos incrementales, que opera también con datos comprimidos y cifrados. Mediante una técnica de delta encoding, permite sincronizar archivos y directorios entre dos máquinas de una red o entre dos ubicaciones en una misma máquina, minimizando el volumen de datos transferidos.
Una característica importante de rsync no encontrada en la mayoría de programas o protocolos es que la copia toma lugar con sólo una transmisión en cada dirección.
Además rsync puede copiar o mostrar directorios contenidos y copia de archivos, opcionalmente usando compresión y recursión.
Migración de un recurso a otro
Vamos a suponer que estamos trabajando en un entorno de producción en el que tenemos un recurso compartido en el que varias aplicaciones escriben datos. Este recurso puede ser una NAS, NFS, CIFs/SAMBA, etc...
Por algún motivo este recurso va a ser migrado a un nuevo recurso que deberemos comenzar a usar.
Dado que estamos en producción, el tiempo de parada y no disponibilidad del servicio debe ser mínimo para el traspaso de los datos de un recurso a otro, además de que no podemos perder nada debemos asegurarnos que los datos del viejo recurso se copian exactamente igual al nuevo destino.
Para realizar este proceso de copia, el mejor sistema que podemos usar es rsync, ya que no sólo copia los ficheros, sino que además mantiene los propietarios de los ficheros, permisos, enlaces y optimiza la copia entre el origen y destino.
La sintaxis básica para usar rsync es: rsync opciones origen destino
NOTA: rsysnc permite copiar ficheros tanto en el mismo servidor como copia a servidores remotos
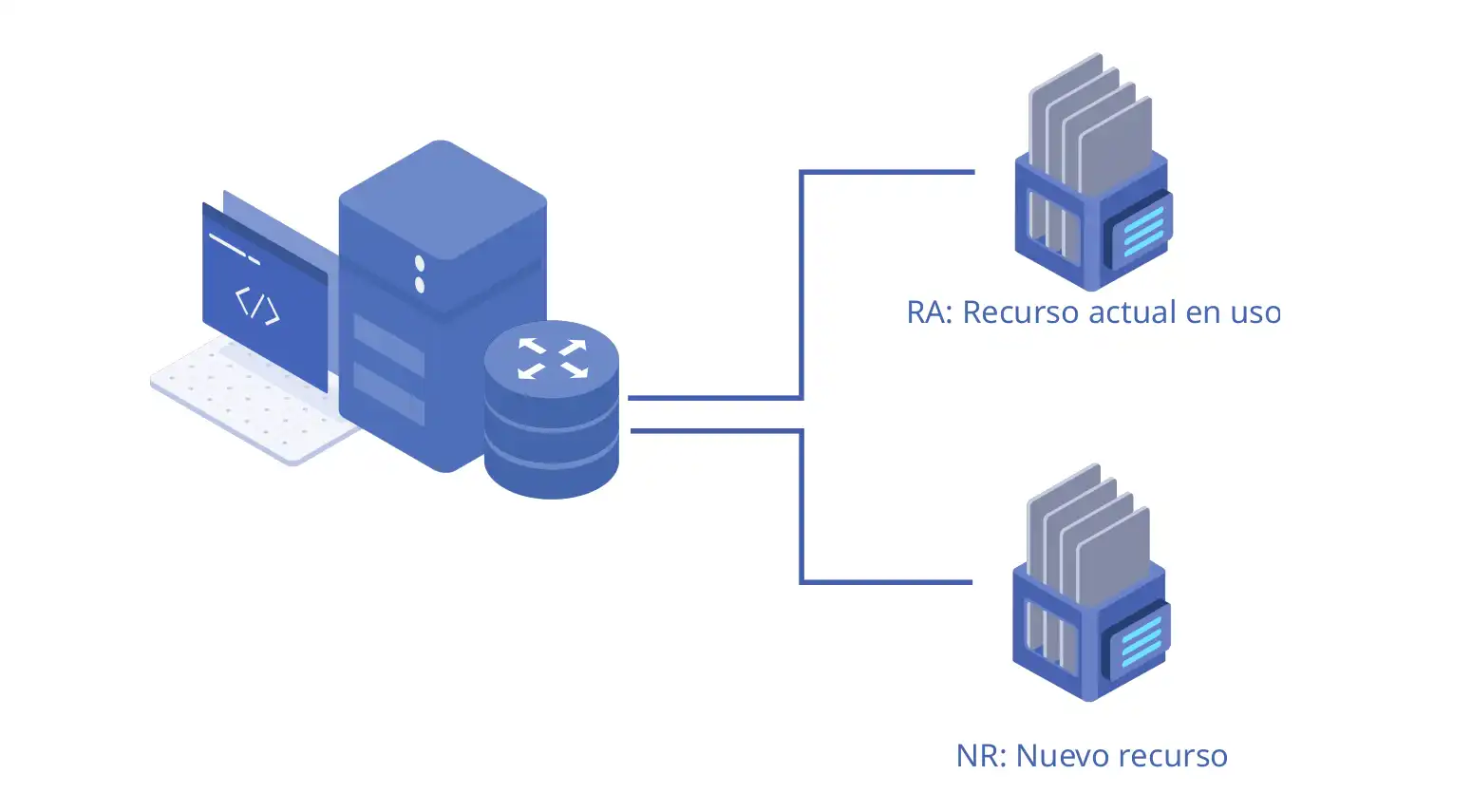
En el gráfico simplificado anterior se ve como sería la situación.
RA sería el recurso que tenemos montando en el servidor de producción donde varias aplicaciones escriben (cada una en su directorio). NR sería el nuevo recurso al que vamos a migrar los datos y donde seguirán escribiendo en el futuro las aplicaciones.
El proceso se puede simplificar en los siguientes pasos:
- Sincronización previa de
RAaNR - Parada de las aplicaciones
- Sincronización final de
RAaNR - Cambio del punto de montaje.
RAse desmonta yNRse monta como punto de montaje enRA, consiguiendo que sea transparente para las aplicaciones.
En el paso 1, se realiza una sincronización inicial para llevarnos toda la estructura y los ficheros que se generan por las aplicaciones, dependiendo del tamaño de los datos (GB o TB) y de la velocidad de lectura/escritura de los recursos usados, este proceso puede durar desde varios minutos a varias horas.
En el paso 2, pararemos las aplicaciones para que no haya nuevas escrituras de datos y poder realizar una copia/sincronización limpia.
El paso 3, sincronizaremos los últimos ficheros escritos para que no haya ninguna discrepancia de datos y esté todo totalmente actualizado
En el último paso 4, desmontamos el recurso RA que estaban usando las aplicaciones y montamos el nuevo recurso NR en la misma ruta que usaban el recurso anterior, para que las aplicaciones y desarrolladores no tengan que modificar nada en su código o configuraciones y sea una migración transparente.
Cuando el tiempo de finalización importa
Aunque rsync es muy rápido, ya que si por ejemplo en un fichero/directorio sólo ha cambiado su fecha de acceso, unicamente se cambiará ese dato, tiene que recorrer toda la estructura de directorios y revisar todos y cada uno de los ficheros existentes, si hay miles de ellos, el tiempo se puede dilatar considerablemente.
El paso 3, en que se realiza la última sincronización es crucial sobre todo en un entorno de producción para minimizar el tiempo de parada y de no disponibilidad de las aplicaciones.
Supongamos la siguiente estructura de directorios para varias aplicaciones:
├── NR
│
├── RA
│ ├── app-01
│ ├── app-02
│ ├── app-03
│ ├── app-04
│ ├── app-05
│ ├── app-06
│ ├── app-07
│ ├── app-08
│ ├── app-09
│ ├── app-10
│ ├── app-11
│ ├── app-12
│ ├── app-13
│ ├── app-14
│ └── app-15
Un proceso normal sería realizar un rsync del directorio RA hacia NR.
Escribo para mayor claridad las opciones extendidas de la sintaxis de rsync.
rsync --archive --delete /RA/ /NR
Usamos --archive ó -a que incluye las opciones -rlptgoD :
Opción archive:
-r : Recursivo
-l : Copiar enlaces como enlaces
-p : Preservar los permisos
-t : Preservar fecha/hora de modificación
-t : Preservar grupo
-o : Preservar propietario
-D : Si algo es un dispositivo o fichero especial también se copia
Usamos la opción --delete para que si algún fichero (por ejemplo ficheros temporales) se han borrado del origen, también se borren en el destino.
NOTA: Importante usar la barra finalRA/después de la ruta del directorio origen, para que se lleve exactamente la estructura de directorios interna y no se cree un nuevo directorioRAdentro deNR
Una primera versión de sincronización sincroniza_v1.sh podría ser:
#!/bin/bash
while true
do
rsync --archive --delete /RA/ /NR
done
Si dejamos este script en un cron, al ser un bucle infinito, cuando finalice la sincronización, volverá a ejecutarse y revisará los cambios y realizará de nuevo la sincronización.
Parece una buena solución, sin embargo, el problema que nos encontramos es que cada directorio app-N puede tener tantos ficheros y subdirectorios, que el rsync de cada directorio de cada aplicación puede durar por ejemplo una hora.
Cuando haya pasado de app-01 y llegue a app-15 habrán pasado aproximadamente unas 15 horas, durante las cuales cada aplicación anterior ha tenido tiempo de generar nuevos ficheros.
En cuanto hagamos la parada de las aplicaciones y vayamos a realizar la última sincronización, el tiempo de parada y sincronización puede llegar a ser de casi 15 horas, lo cual no es aceptable.
Rsync en paralelo
Está claro que el procedimiento se puede reducir si lanzamos varios rsyncindividuales y en paralelo para cada uno de esos directorios, tendríamos 15 procesos de sincronización ejecutándose y en el proceso de parada, la última sincronización duraría unicamente lo que tardase el directorio con mayor número de ficheros, pudiéndose realizar esa migración con una parada de como máximo una hora, algo que empieza a entrar en unos tiempos razonables.
Mientras se realizan esas sincronizaciones en paralelo, nos puede interesar tener datos sobre cuanto tiempo tarda cada uno de ellos, para cuando llegue el momento de la intervención tener una estimación real de cuanto vamos a tardar.
Os dejo y además os explico un script que permite tener un control de tareas de rsync en un servidor sobre varios directorios, y que además deja un LOG con los tiempos de duración de los procesos de sincronización.
#!/bin/bash
# -----------------------------------------------------
# sincroniza.sh
# (c) SoloConLinux
# Sincronizacion paralelizada por directorios
# en modo background con control de ejecucion
# y log de tiempos de sincronizacion
# -----------------------------------------------------
# Variables
FCONTROL="/tmp/sinc"
FLOG="/var/log/sincroniza.log"
# Funciones del script
sincroniza() {
if [ -f $FCONTROL-$2 ] ; then
echo "Ejecutandose proceso $2 de sincronizacion de $1"
else
echo "$(date) Iniciando $1" >> $FLOG
HORAINI=$(date +"%s")
touch $FCONTROL-$2
rsync --archive --quiet --delete /RA/$1/ /NR/$1
echo "$(date) Fin de $1" >> $FLOG
HORAFIN=$(date +"%s")
# Calcular tiempo en segundos (HORAFIN - HORAINI)
TIEMPO=$(($HORAFIN - $HORAINI))
# Transformar segundos en HH:MM:SS
HHMMSS=$(echo - | awk -v "S=$TIEMPO" '{printf "%02d:%02d:%02d",S/(60*60),S%(60*60)/60,S%60}')
# Tiempo de sincronizacion al LOG
echo "*** /RA/$1 ha tardado $HHMMSS en sincronizarse ***" >> $FLOG
rm $FCONTROL-$2
fi
}
# ----- Parte principal del script --------------------------
# Array de Directorios a sincronizar
DIRECTORIOS=(app-01 app-02 app-03 app-04 app-05 app-06 app-07 app-08 app-09 app-10 app-11 app-12 app-13 app-14 app-15)
# Bucle para sincronizar en background
for i in $(echo ${!DIRECTORIOS[@]})
do
# Lanzar sincronizacion de cada elemento (ruta y posicion array)
sincroniza ${DIRECTORIOS[$i]} $i &
done
# -----
El funcionamiento del script es sencillo, lo explico desde la parte principal del script para que se comprenda.
DIRECTORIOSes una array con los directorios que deseamos se sincronicen de RA a NR
El bucle recorre todo el array, y llama a la función sincroniza pasándole 2 parámetros, el primero $1 es el nombre del directorio a sincronizar, y el segundo $2 es el valor numérico del elemento. Además se llama a la función en modo background & para que no espere a la finalización de la ejecución de la función y continúe con el siguiente elemento.
En el primer bucle la llamada a la función interna contendría los siguientes valores:sincroniza app-01 0 &
Veamos que hace la función sincroniza con los valores que recibe.
sincroniza usa un fichero de control para saber si existe algún rsync activo para ese directorio que le hemos indicado, se define a partir de la variableFCONTROL="/tmp/sinc" + la variable $2 que recibe (posición del array)
Si ya hay un proceso rsync ejecutándose para ese elemento, lo sabe porque existirá un fichero de nombre /tmp/sinc-N y no realiza nada.
Si no existe ese fichero de control, se genera. Se apunta en una variable interna de la función la hora de inicio en segundos HORAINI, y se llama al proceso de rsync incluyendo el parámetro --quiet para evitar salida del proceso.
En cuanto el proceso rsync de esa función (que se está ejecutando en segundo plano en una sub-shell) finaliza, se apunta la hora de finalización en segundos HORAFIN, se calcula cuanto ha tardado el proceso de rsync, simplemente restando las tiempos que están en formato segundos, el resultado lo transformamos a un formato legible en formato hh:mm:ss
Los datos del tiempo de sincronización los enviamos al fichero de Log que hemos definido en la variable FLOG.
El último paso es borrar el fichero de control, para que cuando la función sea llamada de nuevo para este directorio en particular se realice de nuevo la sincronización y se vuelvan a monitorizar los tiempos.
Este script lo podemos dejar en un cron que se ejecute por ejemplo cada 5 minutos, ya que como hemos visto, si ya hay un rsync activo para ese directorio no se va a volver a lanzar.
En el caso de que por ejemplo el directorio app-13 tuviese una cantidad enorme de subdirectorios y ficheros podemos incluirlo de forma troceada en el array de directorios para separarlo en procesos de rsync y acelerar la sincronización.
Ejemplo:
├── NR
│
├── RA
│ ├── app-01
│ ├── app-02
│ ├── app-03
│ ├── app-04
│ ├── app-05
│ ├── app-06
│ ├── app-07
│ ├── app-08
│ ├── app-09
│ ├── app-10
│ ├── app-11
│ ├── app-12
│ ├── app-13
│ │ ├── dir-a
│ │ ├── dir-b
│ │ ├── dir-c
│ │ ├── dir-d
│ │ ├── dir-e
│ │ ├── dir-f
│ │ ├── dir-g
│ │ ├── dir-h
│ │ ├── dir-i
│ │ ├── dir-j
│ │ ├── dir-k
│ │ ├── dir-l
│ │ ├── dir-m
│ │ ├── dir-n
│ │ ├── dir-o
│ │ ├── dir-p
│ │ ├── dir-q
│ │ ├── dir-r
│ │ ├── dir-s
│ │ ├── dir-t
│ │ ├── dir-u
│ │ ├── dir-v
│ │ ├── dir-w
│ │ ├── dir-x
│ │ ├── dir-y
│ │ └── dir-z
│ ├── app-14
│ └── app-15
En este caso nuestro array DIRECTORIOS podría contener separados cada uno de los subdirectorios de app-13, con los siguientes valores:
...
# ----- Parte principal del script --------------------------
# Array de Directorios a sincronizar
DIRECTORIOS=(app-01 app-02 app-03 app-04 app-05 app-06 app-07 app-08
app-09 app-10 app-11 app-12 app-13/dir-a app-13/dir-b app-13/dir-c
app-13/dir-d app-13/dir-e app-13/dir-f app-13/dir-g app-13/dir-h
app-13/dir-i app-13/dir-j app-13/dir-k app-13/dir-l app-13/dir-m
app-13/dir-n app-13/dir-o app-13/dir-p app-13/dir-q app-13/dir-r
app-13/dir-s app-13/dir-t app-13/dir-u app-13/dir-v app-13/dir-w
app-13/dir-x app-13/dir-y app-13/dir-z app-14 app-15)
...
El script es mejorable, pero como punto de partida y explicación para uso de procesos en paralelo de rsync creo que es válido y os sea útil.
Evidentemente, tras la última sincronización hay que eliminar el cron que se está ejecutando cada cierto tiempo este script.
Si no queremos que se ejecute ningún proceso de sincronización sobre un directorio podemos crear a mano el fichero de control que evita esa sincronización /tmp/sinc-N, en donde N es la posición de 0-n en el array DIRECTORIOS.
Con los datos sincronizados, cambiaremos en nuestro fichero /etc/fstab el nuevo recurso NR que tiene todos los datos actualizados y sincronizados tenga el punto de montaje que tenía anteriormente RA.
Jugando un poco con el script, las sincronizaciones que os podrían llevar horas se pueden realizar en minutos, lo cual es muy importante en caso de intervenciones en servidores de producción.


